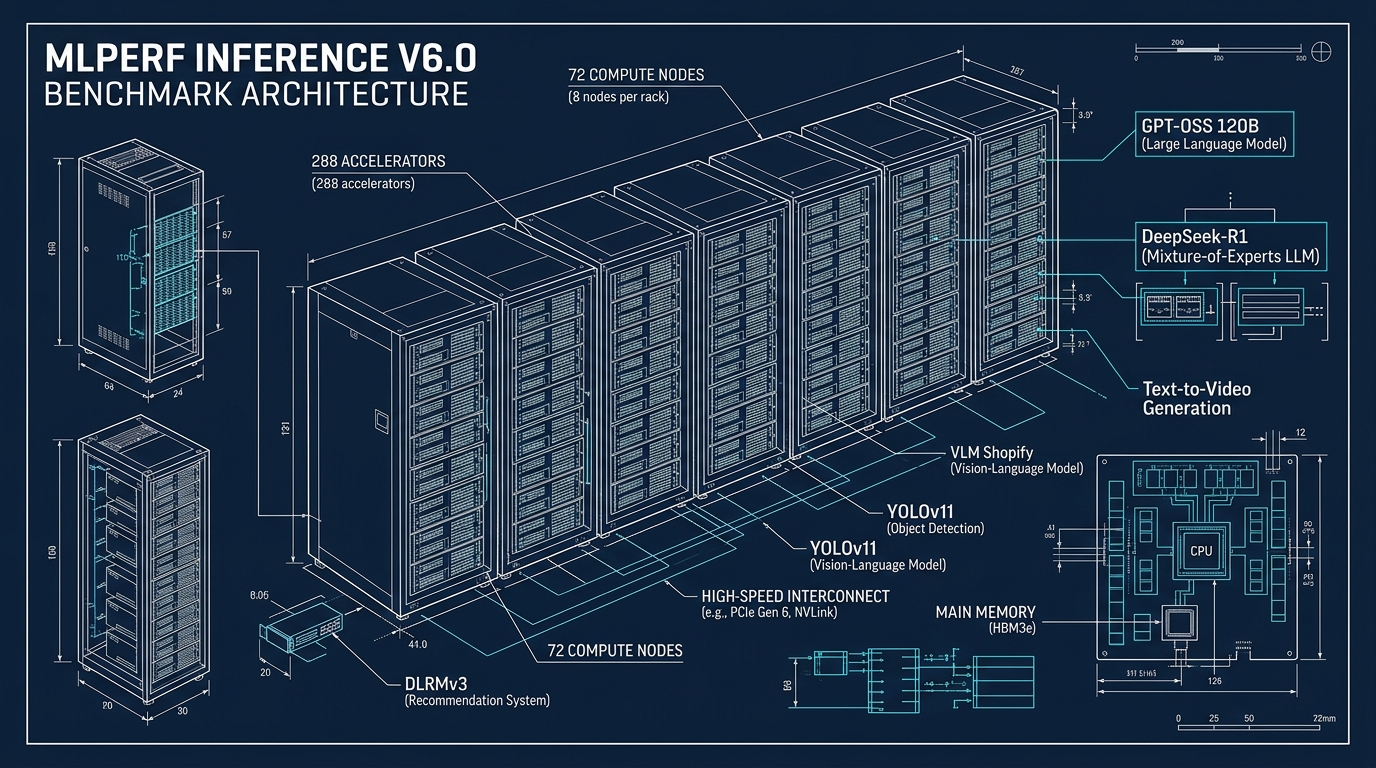
MLCommons a publié les résultats de MLPerf Inference v6.0, sa plus grosse révision depuis le lancement du benchmark. Cinq des onze tests datacenter sont nouveaux ou actualisés, et le suite intègre pour la première fois un test génération vidéo et un benchmark de modèle vision-langage.
La plus grande mise à jour depuis le lancement du benchmark
Annoncée le 29 avril, la version 6.0 ajoute un benchmark LLM open-weight basé sur GPT-OSS 120B, utilisable pour les mathématiques, le raisonnement scientifique et le codage. Le test DeepSeek-R1 sur le raisonnement avancé est étendu à un scénario interactif autorisant le décodage spéculatif. Côté recommandation, DLRMv3 fait son entrée comme premier benchmark séquentiel de la suite, avec une contribution d’ingénierie majeure de Meta.
Trois nouveautés qui collent au marché
Le suite v6.0 introduit aussi le premier benchmark texte-vers-vidéo de MLPerf, un test reflet direct de la vague Sora, Veo et consorts. Un nouveau benchmark vision-langage (VLM) s’appuie sur les données du catalogue produit de Shopify pour transformer du contenu multimodal non structuré en métadonnées exploitables. Enfin, le test de détection d’objets pour les systèmes edge passe au modèle YOLOv11 Large d’Ultralytics, plus représentatif des charges actuelles.
Frank Han, co-président du groupe de travail MLPerf Inference et ingénieur chez Dell, parle de « la révision la plus significative jamais réalisée sur la suite Inference ». L’ampleur des changements vient, selon lui, de la mobilisation des membres qui ont contribué à un effort d’ingénierie inédit pour adapter les tests à la rapidité d’évolution des modèles d’IA.
Les systèmes multi-nœuds prennent le pouvoir
L’autre tendance forte de cette édition concerne l’échelle des systèmes soumis. Les soumissions multi-nœuds bondissent de 30 % par rapport à Inference 5.1, il y a six mois. Plus marquant encore, 10 % des systèmes soumis cette fois comportent plus de dix nœuds, contre 2 % à la session précédente. Le plus gros système soumis embarque 72 nœuds et 288 accélérateurs, soit quatre fois plus de nœuds que le record précédent.
Pour Miro Hodak, co-président du groupe de travail et ingénieur chez AMD, « à mesure que les applications IA passent en production, la demande de systèmes haute performance à grande échelle augmente ». Faire fonctionner ces clusters demande des optimisations sur l’architecture, les interconnexions, le stockage et la pile logicielle, au-delà des défis du nœud unique.
LoadGen++, l’outil que les fournisseurs attendaient
Avec Inference 6.0, les soumissionnaires peuvent utiliser LoadGen++, un nouveau harnais qui permet d’exécuter les LLM avec une pile logicielle de type « serving », proche des déploiements réels. Un outil qui rapproche les conditions de test de la production effective, là où les générations précédentes restaient parfois trop académiques. MLCommons publie également un nouveau tableau de bord en ligne avec filtrage avancé et graphiques personnalisés.
24 organisations soumissionnaires, dont trois nouvelles
Vingt-quatre organisations ont participé à cette édition : AMD, ASUSTeK, Cisco, CoreWeave, Dell, GATEOverflow, GigaComputing, Google, Hewlett Packard Enterprise, Intel, Inventec Corporation, KRAI, Lambda, Lenovo, MangoBoost, MiTAC, Nebius, Netweb Technologies India Limited, NVIDIA, Oracle, Quanta Cloud Technology, Red Hat, Stevens Institute of Technology et Supermicro. Trois primo-soumissionnaires font leur entrée : Inventec, Netweb Technologies India et le Stevens Institute of Technology.
La présence de fournisseurs cloud comme CoreWeave, Lambda et Nebius aux côtés des géants traditionnels confirme la montée en puissance des néo-clouds spécialisés IA dans la course à la performance. Pour les acheteurs de systèmes, MLPerf Inference v6.0 reste l’un des rares points de comparaison neutre permettant d’évaluer ce qui se passe vraiment derrière les chiffres marketing.


