Le NIST vient de publier sa première évaluation indépendante de DeepSeek V4 Pro, le modèle phare du laboratoire chinois. Verdict : huit mois de retard sur la frontière américaine, malgré des scores auto-déclarés qui le présentaient comme un rival direct de GPT-5.4 et Claude Opus 4.6.
L’étude a été réalisée par le Center for AI Standards and Innovation (CAISI), créé en 2026 au sein du National Institute of Standards and Technology pour fournir un référentiel public sur les capacités des grands modèles. C’est la deuxième évaluation officielle d’un modèle DeepSeek par l’agence fédérale, après celle de la première génération début 2026.
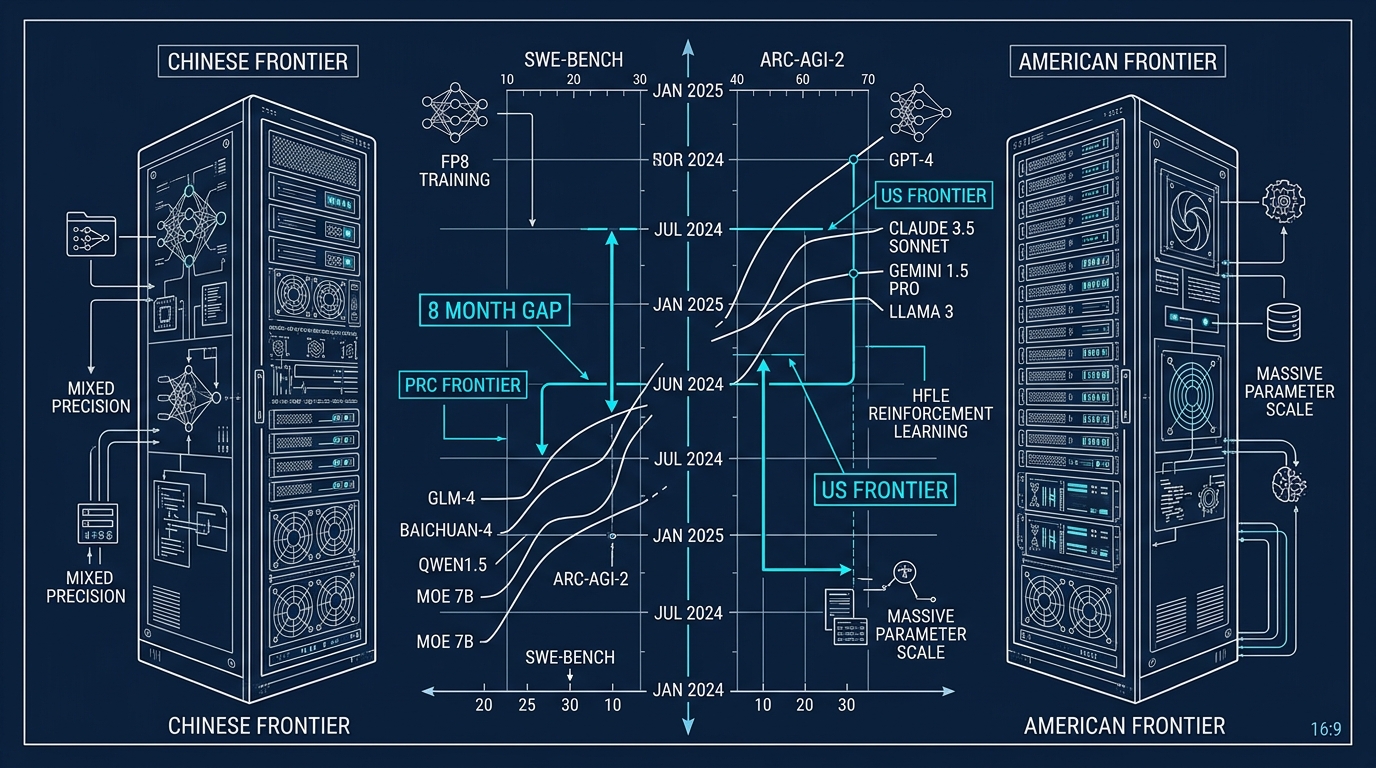
Un retard mesurable de huit mois sur la frontière américaine
Pour fixer le niveau de DeepSeek V4 Pro, le CAISI a utilisé seize benchmarks couvrant cinq domaines : cybersécurité, ingénierie logicielle, sciences naturelles, raisonnement abstrait et mathématiques. L’agrégation passe par une méthode inspirée de l’Item Response Theory, qui calcule un score Elo à partir des résultats sur chaque test.
Le modèle chinois obtient 800 ± 28 points, contre 999 ± 27 pour Claude Opus 4.6 et 1260 ± 28 pour GPT-5.5. En clair, DeepSeek V4 Pro se situe au niveau de GPT-5, sorti il y a huit mois. C’est mieux que ses prédécesseurs, mais l’écart avec les leaders américains s’est légèrement creusé sur la dernière année.
Les benchmarks publics flattent DeepSeek, les benchmarks fermés non
Le CAISI a comparé deux choses : les évaluations publiques choisies par DeepSeek dans son rapport technique, et son propre panel qui inclut des tests non publics. Sur les benchmarks sélectionnés par DeepSeek, le V4 Pro tient effectivement la comparaison avec GPT-5.4 et Opus 4.6.
Mais sur les épreuves tenues hors de portée des entraînements, l’écart se creuse. Sur ARC-AGI-2 semi-private, qui mesure le raisonnement abstrait, DeepSeek obtient 46% contre 79% pour GPT-5.5. Sur PortBench, un test interne du CAISI qui consiste à porter des outils CLI d’un langage à un autre, il plafonne à 44% contre 78%. Sur CTF-Archive-Diamond, le benchmark de cybersécurité offensive du CAISI, il atteint 32%, soit la moitié du score d’Opus 4.6.
Un atout préservé : le coût
Là où DeepSeek garde une vraie carte, c’est sur le rapport coût/performance. Sur sept benchmarks, le V4 Pro est plus économique que GPT-5.4 mini, le modèle américain le plus compétitif côté tarif, dans cinq cas. L’écart va de 53% moins cher à 41% plus cher, selon la charge de travail.
C’est cohérent avec la stratégie connue du laboratoire chinois, qui mise depuis ses débuts sur l’efficacité d’inférence et l’open weights pour compenser un retard capacitaire. Le modèle a été servi par le CAISI sur des GPU H200 et B200 cloud, avec les paramètres recommandés par DeepSeek (température, top_p, budget de tokens).
Pourquoi cette publication est politique
Le calendrier n’est pas anodin. Le CAISI a été créé pour donner à l’administration américaine un thermomètre indépendant, alors que la guerre des classements LLM se joue de plus en plus à coups de communications maison. En mettant des chiffres précis sur l’écart, le NIST alimente le débat sur les contrôles à l’export de GPU et sur le statut des modèles open weights chinois aux États-Unis.
Concrètement, le rapport offre aux décideurs une grille de lecture commune : DeepSeek progresse, mais l’écart frontière reste mesurable. Et il rappelle que les benchmarks publiés par les laboratoires eux-mêmes ne suffisent plus pour positionner un modèle, surtout quand la prochaine vague d’investissements américains se chiffre en centaines de milliards.
Sources : NIST/CAISI.