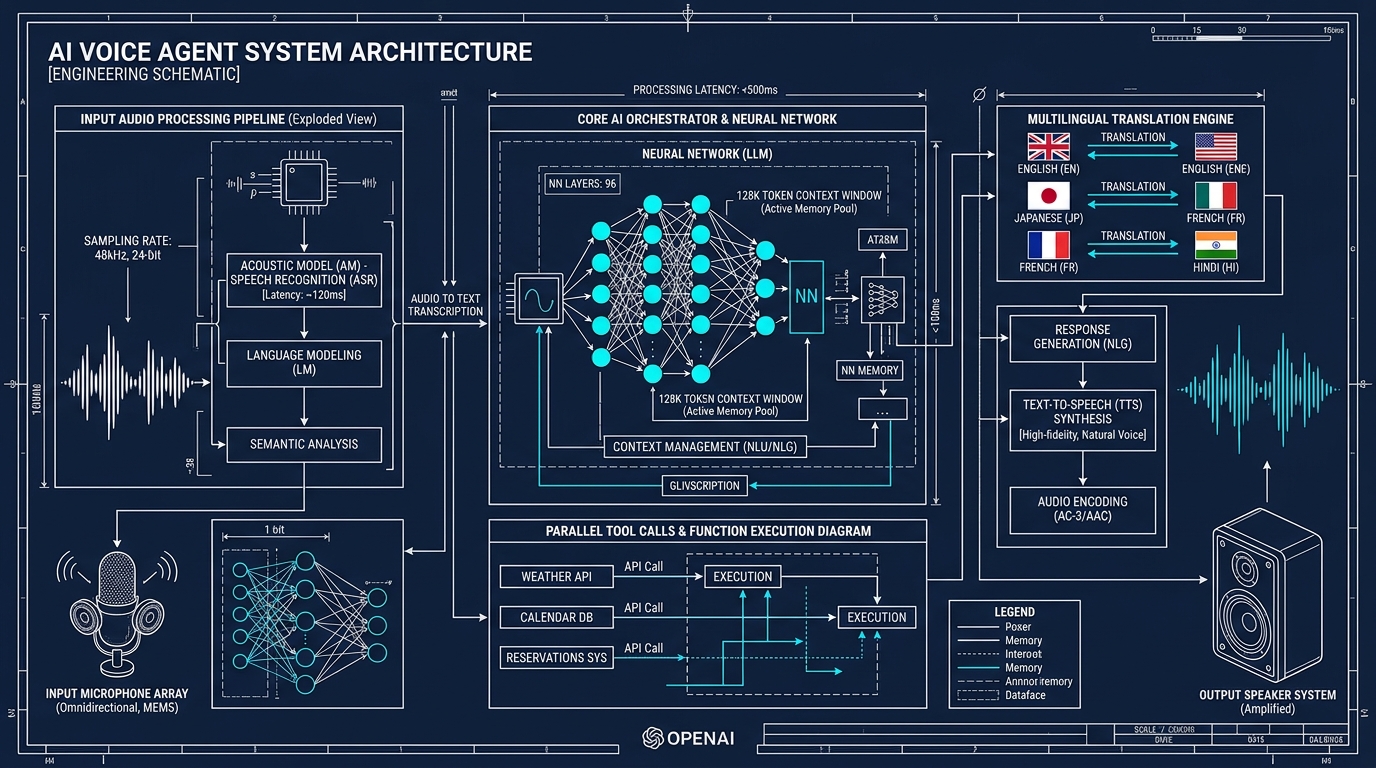
OpenAI a lancé le 7 mai trois nouveaux modèles vocaux pour son API Realtime. Le navire amiral, GPT-Realtime-2, est le premier modèle vocal d’OpenAI doté du raisonnement de classe GPT-5, avec une fenêtre de contexte étendue à 128 000 tokens. Il arrive accompagné de GPT-Realtime-Translate (traduction live de plus de 70 langues vers 13) et de GPT-Realtime-Whisper (transcription en streaming).
L’objectif affiché est clair : faire passer les agents vocaux du simple échange question-réponse à des assistants capables de raisonner, traduire et exécuter des actions pendant que la conversation se poursuit.
Un modèle qui pense avant de répondre
GPT-Realtime-2 introduit plusieurs nouveautés concrètes pour les développeurs. Les « préambules » permettent à l’agent de lâcher des phrases courtes comme « un instant » avant la réponse principale, pour signaler qu’il travaille. Les appels d’outils en parallèle sont désormais audibles : le modèle peut dire « je vérifie votre calendrier » ou « je regarde ça » pendant qu’il interroge un service tiers.
Côté reasoning, OpenAI propose cinq niveaux d’effort : minimal, low, medium, high et xhigh. Les développeurs choisissent leur compromis entre latence et profondeur de raisonnement, avec « low » par défaut. La fenêtre de contexte passe de 32 000 à 128 000 tokens, ce qui ouvre la porte à des sessions vocales beaucoup plus longues sans perte de cohérence.
Les chiffres qui justifient la génération
Sur Big Bench Audio, GPT-Realtime-2 en mode high décroche un score 15,2 % supérieur à GPT-Realtime-1.5. Sur Audio MultiChallenge, qui évalue le suivi d’instructions et la gestion de contexte sur plusieurs tours, GPT-Realtime-2 en mode xhigh fait 13,8 % de mieux que la génération précédente.
Le retour de Zillow, partenaire pilote, est encore plus parlant : sur leur benchmark adversarial le plus difficile, le taux de réussite des appels passe de 69 % à 95 %, soit 26 points de progression. La société immobilière développe avec ce modèle un assistant capable de traiter des requêtes du type « trouve-moi des maisons dans mon budget, évite les rues passantes et programme une visite samedi ».
Translate et Whisper, deux compagnons spécialisés
GPT-Realtime-Translate cible le voice-to-voice multilingue. Deux interlocuteurs parlent dans leur langue, le modèle traduit en temps réel sans rompre le rythme. BolnaAI rapporte 12,5 % de Word Error Rate en moins sur l’hindi, le tamoul et le télougou par rapport aux modèles concurrents. Deutsche Telekom teste le modèle pour son support client multilingue.
GPT-Realtime-Whisper assure la transcription live à faible latence, avec un curseur de réglage entre vitesse et qualité. Cas d’usage : sous-titres en direct de réunions, prise de notes qui suit la conversation, agents vocaux qui restent collés à l’utilisateur.
Pricing et disponibilité immédiate
GPT-Realtime-2 est facturé 32 dollars par million de tokens audio en entrée, 64 dollars en sortie, avec un tarif réduit à 0,40 dollar pour les inputs cachés. GPT-Realtime-Translate est à 0,034 dollar la minute, GPT-Realtime-Whisper à 0,017 dollar la minute. Les trois modèles sont disponibles immédiatement sur l’API Realtime, qui supporte le data residency européen.
Pour l’écosystème robotique, la disponibilité de modèles vocaux qui raisonnent localement et appellent des outils en parallèle ouvre la voie à des humanoïdes ou robots de service capables de tenir une vraie conversation, en plusieurs langues, tout en exécutant des tâches concrètes. Priceline travaille déjà sur un agent voyage capable de gérer une réservation entière à la voix, y compris les changements en temps réel et la traduction sur le terrain.
OpenAI marque ici un point important face à la concurrence vocale, notamment les modèles de Google et d’ElevenLabs. Le combo raisonnement plus traduction plus transcription, livré sur la même API, va probablement pousser plusieurs concurrents à accélérer leurs propres roadmaps audio.


