DeepSeek a mis en ligne ce vendredi la preview de son modèle V4, plus d’un an après le R1 qui avait secoué les marchés tech en janvier 2025. La startup de Hangzhou propose deux variantes, V4-Pro et V4-Flash, avec un contexte de 1 million de tokens par défaut et des poids publiés sur Hugging Face. L’entièreté de la gamme est disponible via son API au tarif annoncé de 0,28 dollar par million de tokens en sortie pour V4-Flash, une rupture nette avec les prix des modèles propriétaires.
Deux modèles, une même promesse d’ouverture
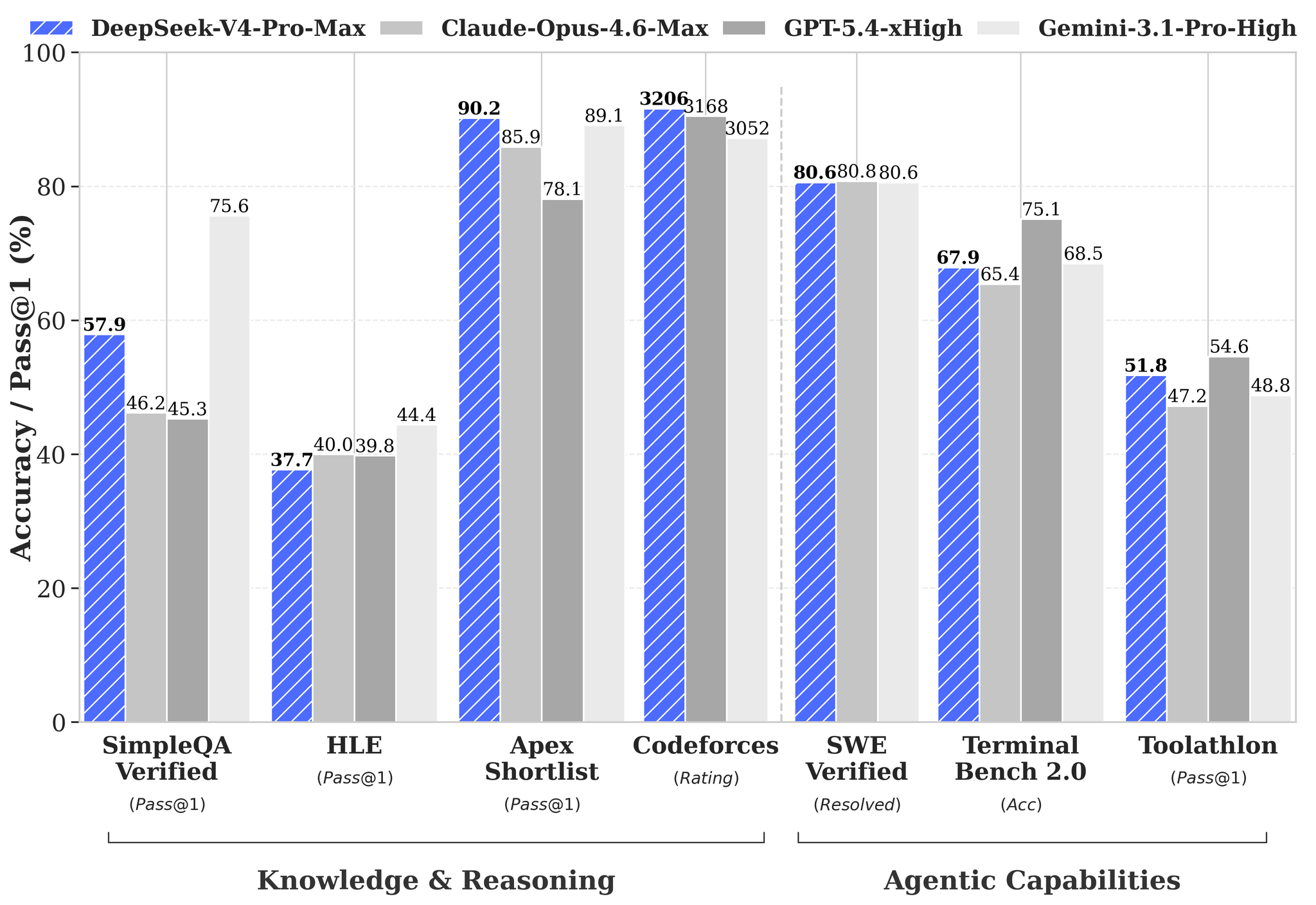
DeepSeek-V4-Pro affiche 1,6 téraparamètre au total, dont 49 milliards sont activés à chaque requête grâce à son architecture Mixture-of-Experts. Le modèle revendique le statut d’open source state-of-the-art sur les benchmarks de code agentique, arrive en tête des modèles ouverts pour les connaissances générales et se classe derrière Gemini-3.1-Pro de Google. Côté raisonnement mathématique et scientifique, DeepSeek affirme dépasser l’ensemble des modèles open source et rivaliser avec les meilleures offres propriétaires.
V4-Flash est la version compacte, 284 milliards de paramètres totaux et 13 milliards actifs. Elle reprend le même contexte d’un million de tokens et revendique des performances proches de celles du Pro sur les tâches d’agents simples. L’écart se creuse sur les problèmes complexes, mais DeepSeek assume un positionnement axé sur le débit, la latence et le prix à l’usage.
Contexte d’un million de tokens par défaut
L’élément central de cette génération est l’attention sparse DeepSeek, couplée à une compression token par token. Cette architecture permet à la famille V4 de tenir un contexte d’un million de tokens sans exploser les coûts de calcul et de mémoire. Jusqu’ici, seules quelques offres fermées comme Gemini proposaient ce type de fenêtre. DeepSeek l’installe par défaut dans ses services officiels et ouvre les poids à la communauté.
Les deux modèles intègrent par ailleurs un double mode « Thinking » et « Non-Thinking », qu’il est possible de basculer depuis l’API. Le mode Thinking fait appel à un raisonnement en chaîne explicite, plus long mais plus précis, tandis que le mode Non-Thinking privilégie la rapidité.
Optimisé pour les agents de code
DeepSeek insiste lourdement sur les usages agentiques. Le modèle a été optimisé pour fonctionner nativement avec Claude Code d’Anthropic, OpenCode et OpenClaw, trois assistants de développement qui pilotent eux-mêmes une chaîne de commandes. La société précise qu’elle utilise déjà V4 en interne pour son propre développement logiciel.
Pour Neil Shah, vice-président de la recherche chez Counterpoint Research, « cette preview est une vraie démonstration de force ». Wei Sun, analyste principale IA du même cabinet, estime que V4 offre « d’excellentes capacités d’agent à un coût largement inférieur » à la concurrence.
Les puces chinoises en embuscade
Le jour même de la publication, Huawei a confirmé que son cluster de calcul IA à base de processeurs Ascend pouvait faire tourner V4. La part exacte des puces domestiques dans l’entraînement initial reste floue, Nvidia gardant un rôle important, mais la capacité à exécuter nativement sur du matériel chinois renforce le positionnement politique de DeepSeek. En bourse, les fondeurs sous contrat SMIC et Hua Hong ont gagné respectivement 9 % et 15 % à Hong Kong sur la séance.
Le marché avait anticipé l’arrivée de V4, et l’onde de choc est moins forte que pour R1. Mais la combinaison poids ouverts, contexte d’un million de tokens et prix cassés recadre la discussion en Chine même. Pour Ivan Su, analyste chez Morningstar, « cette offre positionne clairement les autres modèles ouverts chinois comme concurrents directs », une dynamique que R1 n’avait pas provoquée. Alibaba Qwen, MiniMax, ByteDance et Zhipu sont prévenus : la barre vient d’être relevée au sein même du camp chinois.


