Pendant que le secteur débat de savoir quel modèle d’IA est le plus intelligent, DeepSeek s’attaque à un problème plus terre à terre : faire tourner les modèles plus vite. Le laboratoire chinois vient de publier sur son dépôt GitHub un framework d’accélération baptisé DSpark, conçu pour éliminer les goulots d’étranglement qui pénalisent les grands modèles de langage en forte charge.
Un papier co-signé par le fondateur
L’origine de la recherche retient l’attention. Le papier a été co-publié par DeepSeek et l’université de Pékin, avec le fondateur du laboratoire, Liang Wenfeng, listé comme auteur. Son titre complet : DSpark, Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation.
L’équipe ne s’est pas arrêtée à la publication. Elle a aussi ouvert les poids du modèle DSpark, diffusé DeepSpec, un dépôt de code d’entraînement pour le décodage spéculatif, et testé la compatibilité avec plusieurs plateformes. Une démarche typique de DeepSeek : rigueur académique et application immédiate, le tout en open source.
Pourquoi la vitesse des LLM est un vrai problème
Les modèles actuels génèrent du texte de façon autorégressive. Chaque nouveau token, soit un fragment de mot, exige un passage complet à travers tout le réseau de neurones, en s’appuyant sur l’ensemble des tokens précédents. Résultat : plus la réponse est longue, plus l’attente s’allonge.
Ce fonctionnement crée deux ennuis en production. D’abord une faible utilisation des GPU, donc du matériel mal exploité. Ensuite des temps d’attente excessifs pour l’utilisateur, chaque token ajoutant de la latence. Ces blocages frappent surtout les assistants en temps réel, les enchaînements d’agents multi-étapes et les scénarios à forte concurrence, quand de nombreux utilisateurs sollicitent le service en même temps.
Comment fonctionne DSpark
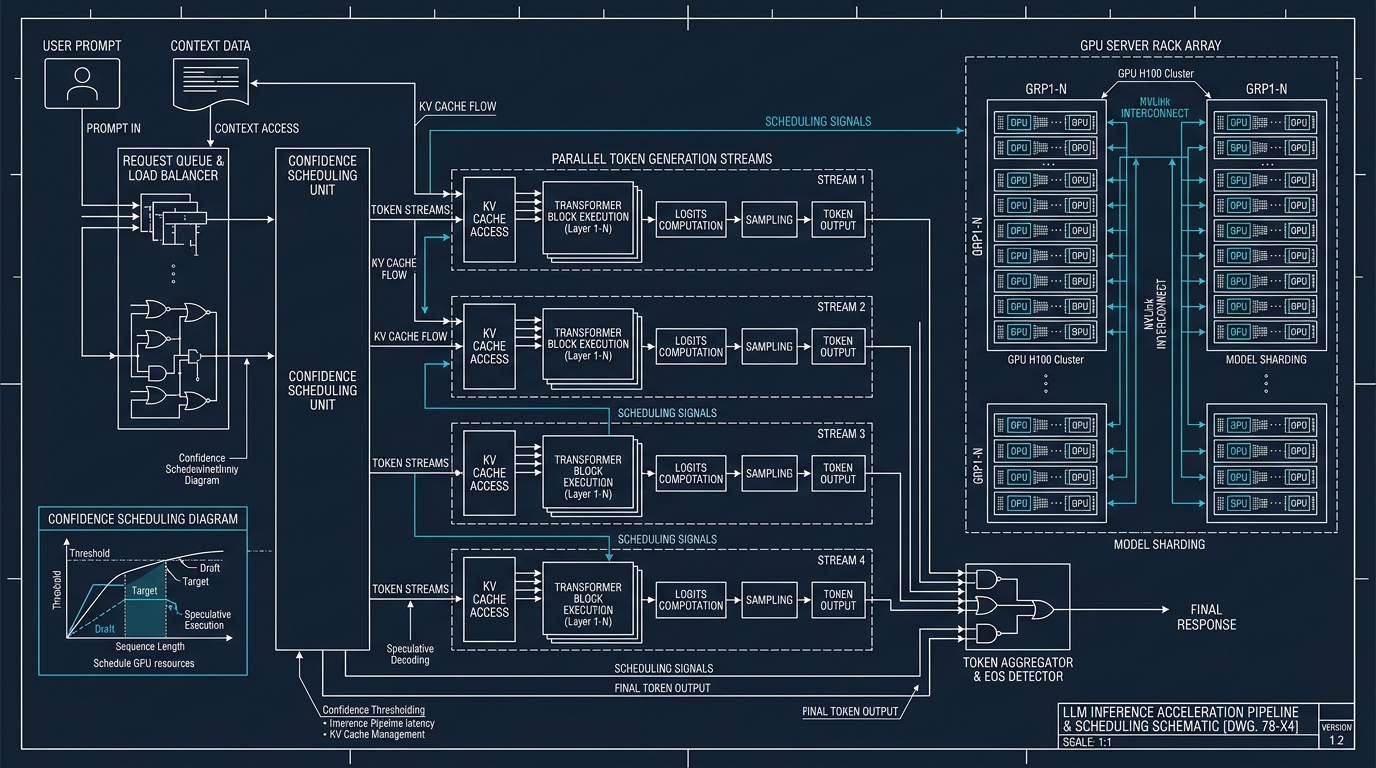
DSpark repose sur une architecture semi-autorégressive, un compromis entre deux exigences contradictoires : produire des tokens brouillon rapidement en parallèle, puis les vérifier efficacement en s’adaptant à l’état réel du serveur. Le framework combine deux innovations. Une génération parallèle à haut débit, qui rédige plusieurs tokens d’un coup au lieu d’attendre chacun à la file. Et une vérification consciente de la charge, qui ajuste sa stratégie selon le trafic du moment.
Les chiffres avancés sont parlants. En production réelle sur DeepSeek-V4, DSpark améliore la vitesse de génération de 60 à 85 %. Sur d’autres modèles, dont Qwen d’Alibaba, il augmente de 16 à 31 % le nombre de tokens acceptés par tour. En publiant méthode, code et poids d’un coup, DeepSeek confirme son pari : se poser en référence de l’efficacité de l’IA plutôt que de la seule puissance brute.