Le laboratoire chinois DeepSeek vient de publier le rapport technique complet de DeepSeek V4, sa nouvelle famille de modèles open source. Le mouvement remet la pression sur OpenAI, Google et Anthropic, mais la vraie nouveauté n’est pas là où on l’attend. Ce n’est pas la taille brute du modèle qui compte, c’est sa capacité à tourner beaucoup moins cher que les concurrents propriétaires grâce à un choix radical de précision numérique.
Deux modèles, deux marchés
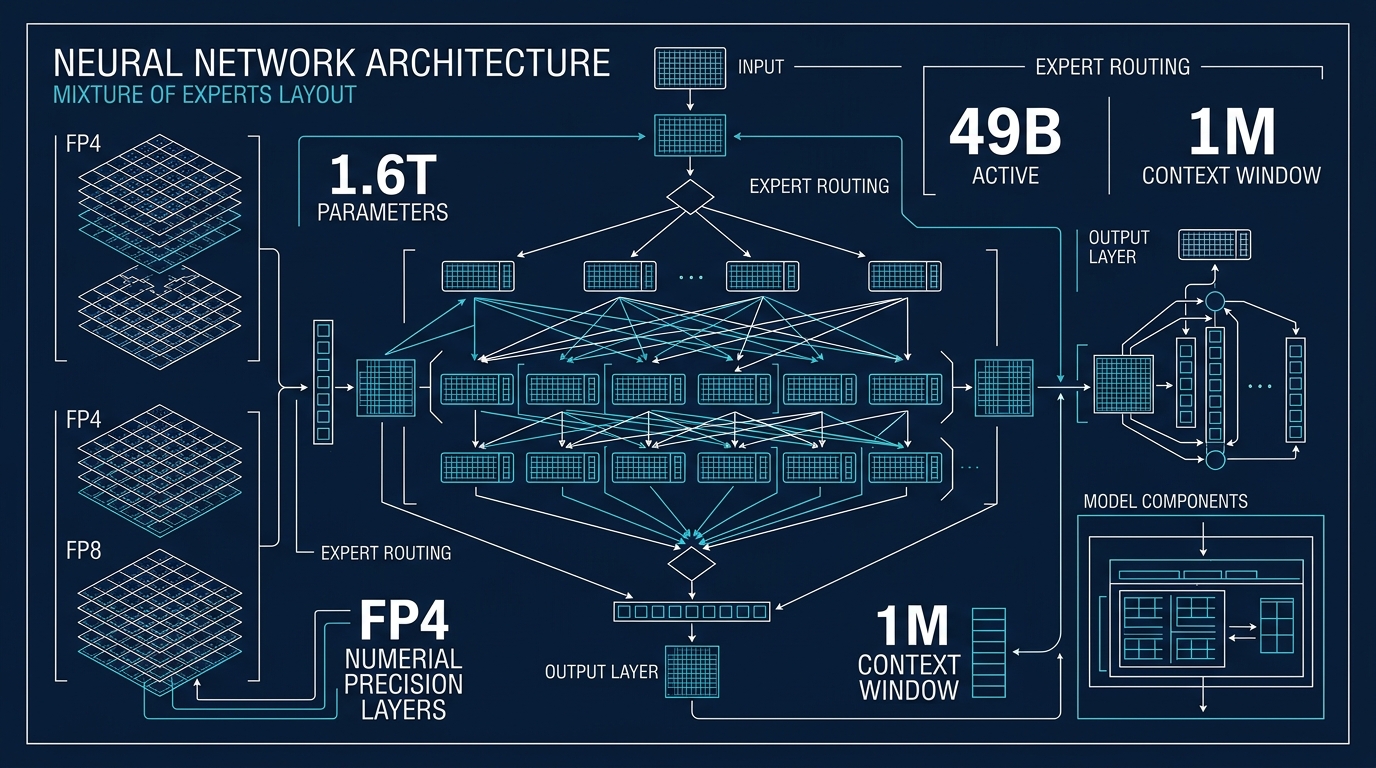
La famille comporte deux références. DeepSeek-V4-Pro affiche 1,6 trillion de paramètres totaux pour 49 milliards actifs par token, et DeepSeek-V4-Flash descend à 284 milliards totaux pour 13 milliards actifs. Les deux modèles supportent un contexte d’un million de tokens, et DeepSeek les positionne moins comme des chatbots que comme des infrastructures pour agents de codage, agents de recherche et workflows d’outillage longue durée.
Concrètement, c’est l’enjeu coût qui change la donne. Selon une analyse Hugging Face de la sortie, à un million de tokens en contexte, V4-Pro consomme 27 % des FLOPs d’inférence par token de DeepSeek-V3.2 et seulement 10 % de sa mémoire KV cache. V4-Flash tombe à 10 % et 7 %. Côté communauté Reddit LocalLLaMA, des utilisateurs rapportent un coût d’inférence divisé par 17 par rapport à V3.
FP4, le pari technique de l’année
Le choix le plus tranchant de V4 concerne la précision numérique. Les modèles instruct utilisent du FP4 pour les poids des experts du Mixture of Experts, et du FP8 pour la majorité du reste de la pile. Les notes de déploiement de vLLM pointent du MXFP4 pour les experts avec scales en FP8.
En clair, DeepSeek compresse fortement les couches d’experts coûteuses tout en gardant assez de précision autour pour ne pas effondrer la qualité. Et surtout, la chose est faite avec du quantization-aware training, c’est-à-dire que la contrainte basse précision est intégrée pendant l’entraînement, pas appliquée après. Pour un système MoE où les poids des experts dominent le stockage et la bande passante, c’est un changement majeur.
Pour les startups IA, le message est limpide. Si le FP4 tient ses promesses sous des charges réelles, le coût de service peut chuter sans imposer aux équipes de basculer sur des petits modèles. La pression mémoire en moins change aussi la conversation hardware. Un fondateur qui hésitait entre une API fermée, un modèle ouvert hébergé et un cluster auto-géré dispose maintenant d’une nouvelle variable à tester.
L’ingénierie de stabilité, l’autre marqueur
La basse précision n’a d’intérêt que si le modèle reste entraînable. V4 ajoute plusieurs choix de stabilité autour de ce problème. Le papier décrit des manifold-constrained hyper-connections, qui remplacent les connexions résiduelles classiques par une structure de mélange plus contrôlée. Il utilise aussi l’optimiseur Muon pour la majorité des paramètres, en gardant AdamW pour les embeddings, têtes de prédiction, biais et normalisations.
Ces détails paraissent académiques jusqu’à ce qu’on les relie au coût. Une instabilité d’entraînement gaspille du calcul, et un run raté en gaspille encore plus. Si DeepSeek améliore la convergence en poussant les poids en FP4 et FP8, l’avantage n’est pas seulement à l’inférence. C’est aussi un chemin vers du développement de modèle plus efficace, en particulier pour les équipes qui doivent itérer vite.
La pression sur l’open source mondial
DeepSeek met aussi la pression sur l’écosystème open source dans son ensemble. Qwen et Llama ont rendu accessibles des modèles capables hors des labos frontière fermés, mais V4 pousse la conversation vers la conception système. La question n’est plus seulement de savoir si un modèle ouvert peut performer face au propriétaire. C’est de savoir si une release open peut livrer en même temps les kernels, les formats de quantization, les choix de routing et les patterns de service nécessaires pour la rendre économiquement utile.
Selon le National Review, V4 est aussi optimisé pour les dernières puces Huawei. Le détail compte sur le plan géopolitique. Les contrôles d’export américains ont forcé les laboratoires chinois à composer avec un hardware national, et ce levier se retourne désormais en avantage compétitif sur la stack logicielle.
Reste à voir si les frameworks SGLang et vLLM tiendront la cadence en production, et si les promesses du papier survivront aux benchmarks indépendants. Mais le signal envoyé est clair. La prochaine vague de compétition IA pourrait être gagnée par les équipes qui comprennent la précision, la mémoire, le routing et la stabilité comme leviers produit, pas seulement comme paramètres techniques.