Google vient de publier un modèle de langage qui ne génère plus le texte mot après mot. Baptisé DiffusionGemma, ce modèle ouvert produit des blocs entiers de 256 jetons à la fois, en partant d’un bruit aléatoire qu’il affine au fil de plusieurs passages. Résultat : jusqu’à quatre fois plus rapide qu’un modèle classique sur une seule carte graphique.
Un texte qui émerge du bruit, comme une image
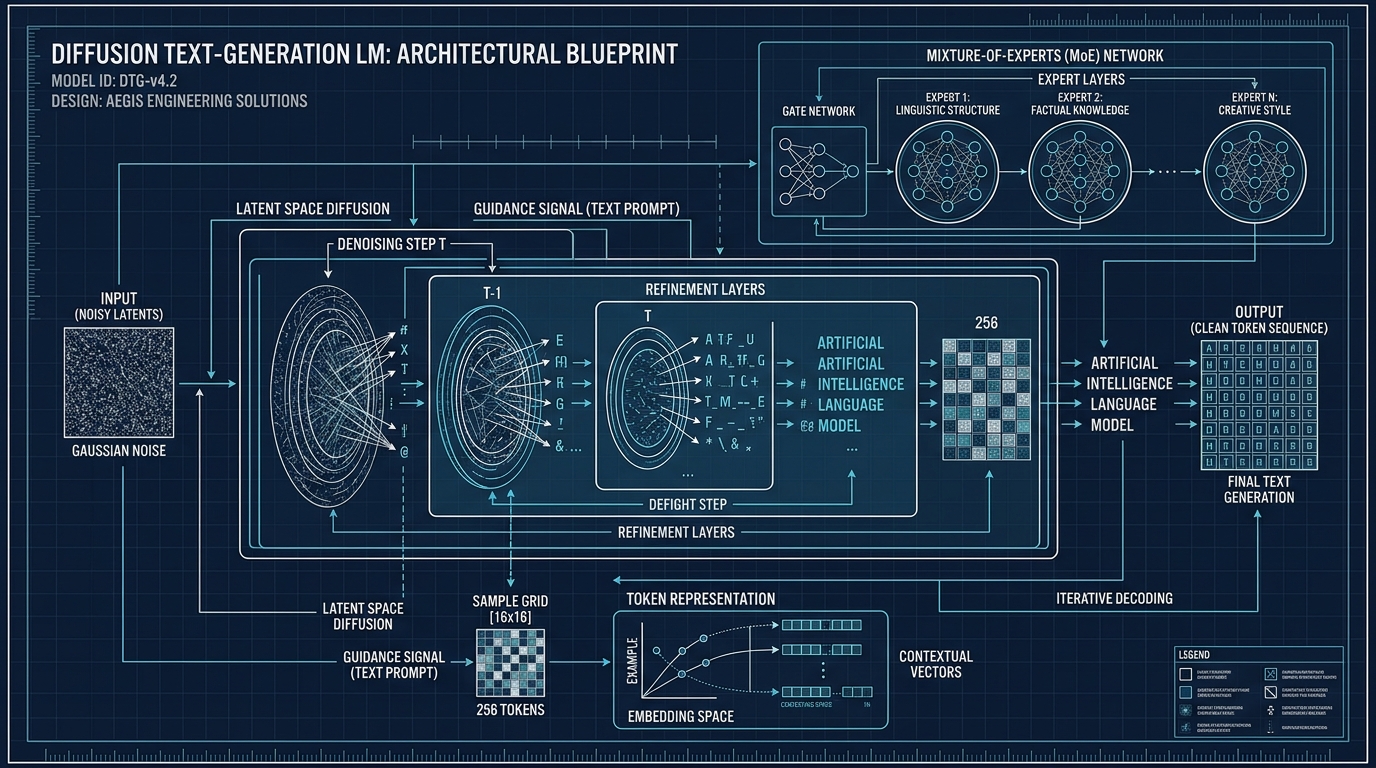
La plupart des modèles de langage actuels fonctionnent de façon autorégressive : ils génèrent un jeton, puis le suivant en s’appuyant sur le précédent, et ainsi de suite. DiffusionGemma emprunte une autre voie, directement inspirée de l’IA de génération d’images. Il démarre avec 256 jetons aléatoires et les débruite progressivement jusqu’à faire apparaître un texte lisible.
Sous le capot, le modèle compte 26 milliards de paramètres mais n’en active que 3,8 milliards à chaque étape, grâce à une architecture de type «mixture of experts» où seuls les sous-réseaux pertinents s’activent. Une fois quantifié en basse précision, il tient dans 18 Go de mémoire vidéo, soit la portée de cartes grand public haut de gamme. Le modèle s’appuie sur la famille Gemma 4 et reprend le procédé de diffusion exploré l’an dernier avec Gemini Diffusion.
Des gains de vitesse spectaculaires sur GPU dédié
L’optimisation a été confiée à Nvidia, qui explique l’avantage par une meilleure utilisation du matériel. Avec les modèles classiques, l’inférence pour un seul utilisateur est souvent bridée par la bande passante mémoire : les unités de calcul du GPU restent inactives à attendre les données. En traitant 256 jetons en parallèle, DiffusionGemma déplace le goulot d’étranglement vers le calcul brut et garde les puces occupées.
Les chiffres annoncés parlent d’eux-mêmes. Nvidia rapporte environ 1 000 jetons par seconde sur une H100 pour une seule requête, et Google revendique plus de 700 jetons par seconde sur une GeForce RTX 5090. En mode local mono-utilisateur, le modèle tourne environ quatre fois plus vite qu’un équivalent autorégressif.
De la vitesse au prix de la qualité
Ce gain a une contrepartie. Dans ses propres tests, Google reconnaît que DiffusionGemma tourne environ trois fois et demie plus vite qu’un Gemma 4 de taille comparable, mais reste en retrait sur chaque épreuve de qualité. La firme recommande donc ses modèles Gemma 4 classiques quand la précision prime, et présente DiffusionGemma comme un outil pour chercheurs et développeurs qui expérimentent des flux locaux et rapides.
Le modèle brille surtout sur les tâches qui ne se lisent pas de gauche à droite. Comme il considère tout le bloc d’un coup, chaque jeton peut faire référence aux autres, y compris ceux qui viennent après. Cela le rend utile pour insérer du texte dans un paragraphe existant, combler des trous dans du code ou travailler sur des données structurées comme des séquences d’acides aminés. Google cite un exemple frappant : une version affinée du modèle résout des grilles de Sudoku, un exercice où les modèles classiques trébuchent car chaque case dépend des suivantes.
Poids ouverts et support large dès le premier jour
Les poids du modèle sont disponibles sur Hugging Face sous licence Apache 2.0. DiffusionGemma fonctionne directement avec les bibliothèques d’inférence courantes comme Transformers, vLLM et MLX. Pour le fine-tuning, Google renvoie vers sa propre boîte à outils JAX, ainsi que vers Unsloth et le framework NeMo de Nvidia. Le support de llama.cpp est prévu.
En ouvrant son modèle si largement, Google envoie un signal clair. La diffusion appliquée au texte n’est plus une curiosité de laboratoire : la startup Inception poursuit la même piste avec son Mercury 2, et plusieurs acteurs misent désormais sur cette approche parallèle pour casser le mur de la vitesse d’inférence.


